
自己的做法
算法思想
使用map集合,数组的值作为key,数组索引作为value。
遍历数组,在map中查找是否有key相等的元素,如果没有,则将当前数组值和索引插入map集合;
如果有,则用当前索引 - map集合相等的索引,如果小于等于k,则直接返回true;
如果大于,则将map集合值相等的对应索引改为当前索引。
注:因为如果当前索引 - map集合中索引已经大于k,那么数组后面的元素一定更大于K,所以应将map集合索引改为当前索引。
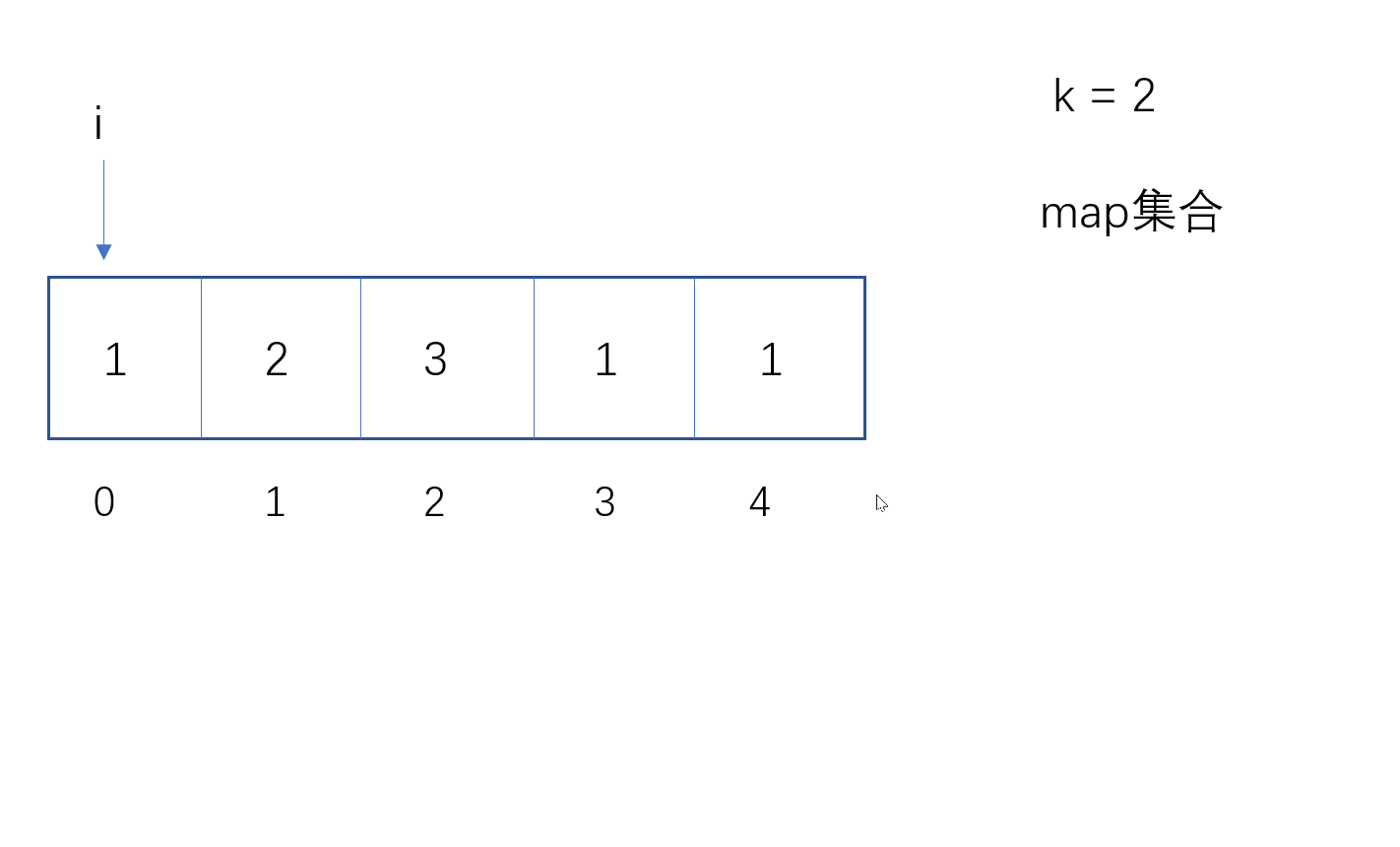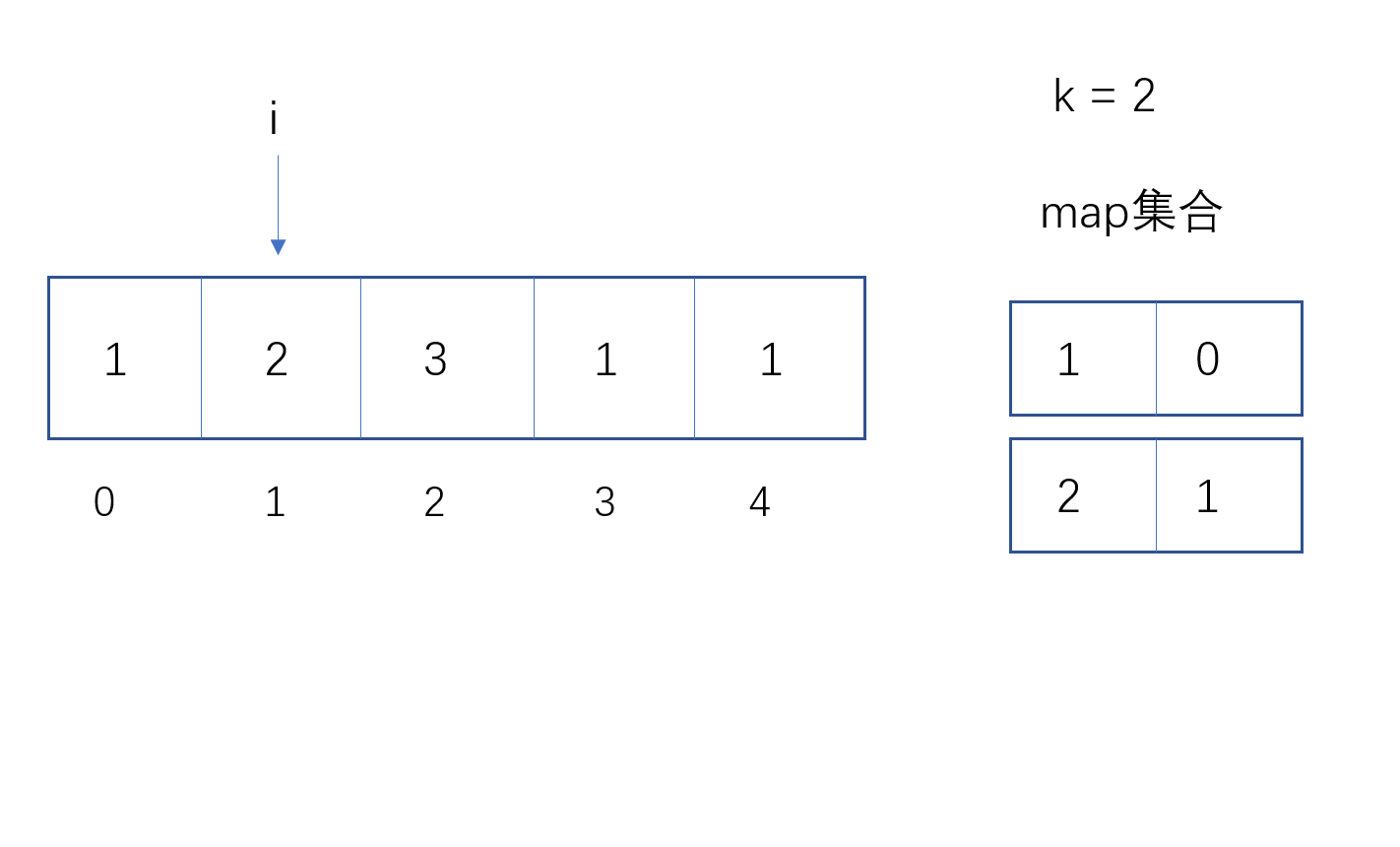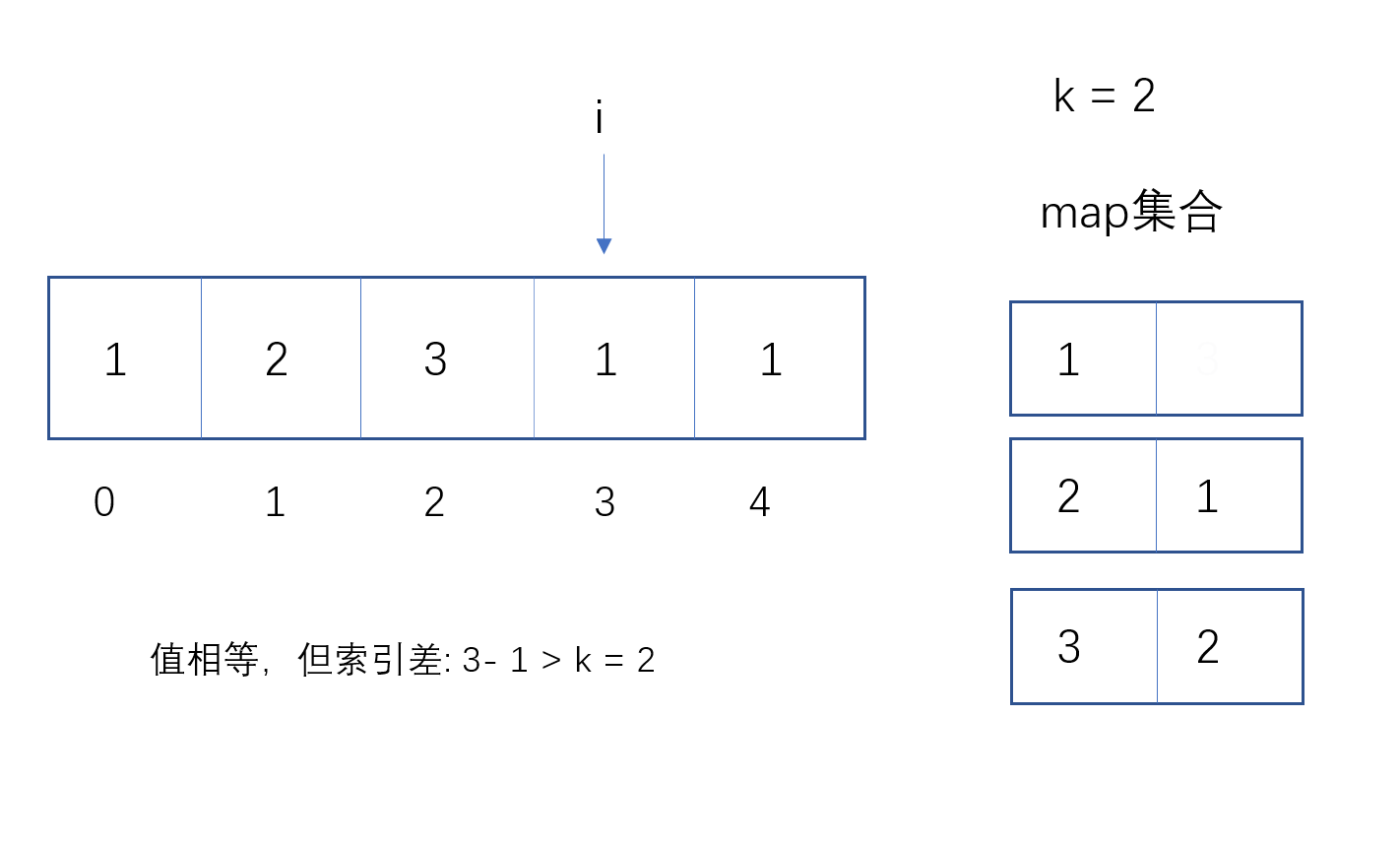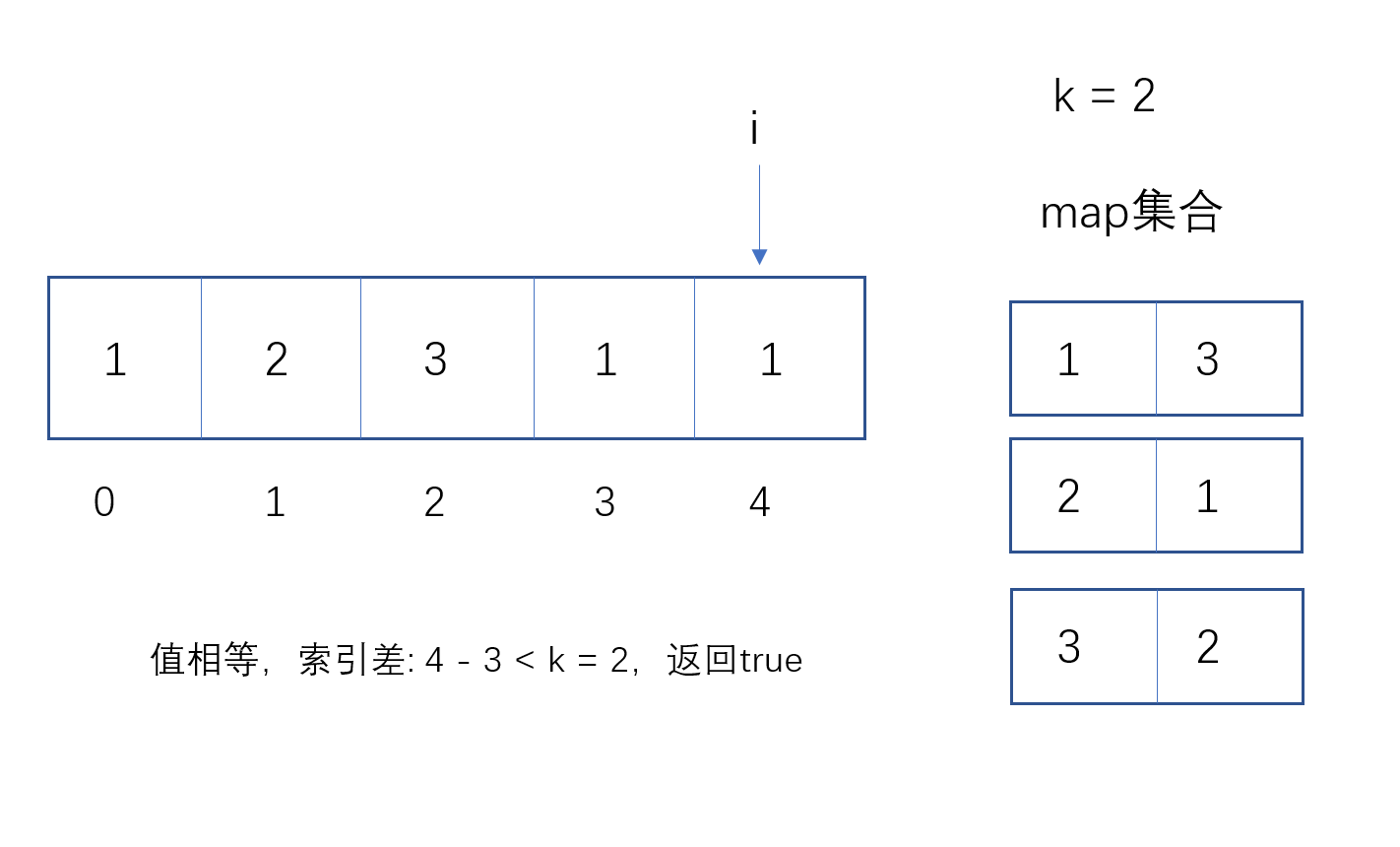
注:动画有个错误,第一个索引差 应该是 3 - 0 > k = 2。
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| class Solution {
public:
static bool containsNearbyDuplicate(vector<int>& nums, int k) {
map<int, int> numbers;
for(int i = 0; i < nums.size(); i++) {
if(numbers.count(nums[i]) == 0) {
numbers.insert({nums[i], i});
} else {
if(i - numbers.at(nums[i]) <= k) {
return true;
} else {
numbers.at(nums[i]) = i;
}
}
}
return false;
}
};
|
性能分析
时间复杂度:遍历数组,O(n)。
空间复杂度:O(n)。
官方做法
哈希表
算法思想
使用哈希表来存储数组值,遍历数组,查找哈希表是否存在相等的元素,如果没有,则存入当前元素,并判断哈希表长度是否大于k,如果大于,则删除最旧的元素(即最先加入来的元素);
如果存在相等元素,返回true。
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class Solution {
public:
static bool containsNearbyDuplicate(vector<int>& nums, int k) {
set<int> number;
for(int i = 0; i < nums.size(); i++) {
if(number.count(nums[i]) == 1) {
return true;
}
number.insert(nums[i]);
if(number.size() > k) {
number.erase(nums[i - k]);
}
}
return false;
}
};
|
性能分析
时间复杂度:O(n)。
空间复杂度:O(n)。