
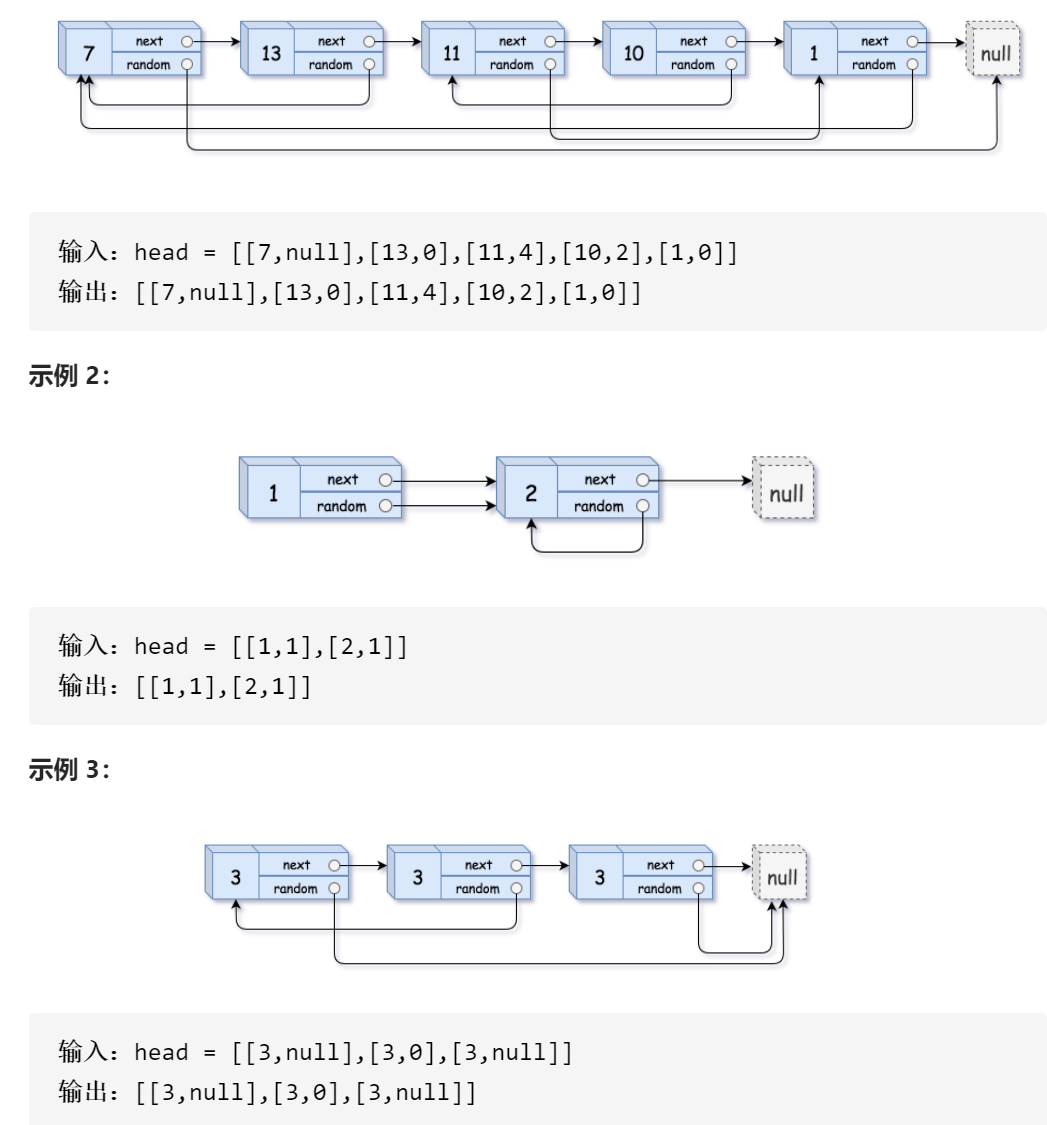
自己的做法
算法思想
其实就是根据给定链表复制一个新链表,只不过多了random指针。它指向链表任意一个节点或者null。
因为链表中节点值有可能重复,所以不能以节点值为依据来判断该指向哪个节点。
而链表中索引是一定的,所以我是用索引来决定random指针该指向哪个节点。
设给定链表为head,复制的新链表为newHead。
所以首先创建index数组,来存放head链表每个节点的random指针指向的节点 在head链表中的索引,以0开始。如果指向null,则为-1。
因为random任意指,所以每访问一个节点,都需要遍历一遍链表。
然后按照head链表,创建newHead链表,先不管random指针。
然后将newHead链表每个节点的指针依次放入数组中,来建立索引。
然后依据索引数组,设置newHead链表每个节点的random指针应指向的节点。
如果索引为-1,则指向null。
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) {return nullptr;}
vector<int> index;
Node * cur = head;
while (cur) {
if(cur->random == nullptr) {
index.push_back(-1);
} else {
Node * temp = cur->random;
Node * node = head;
int count = 0;
while (node) {
if(temp != node) {
count++;
} else {
index.push_back(count);
}
node = node->next;
}
}
cur = cur->next;
}
Node * newHead = new Node(head->val);
Node * pre = newHead;
Node * node = head->next;
vector<Node *> nodes;
nodes.push_back(newHead);
while (node) {
Node * temp = new Node(node->val);
nodes.push_back(temp);
pre->next = temp;
pre = temp;
node = node->next;
}
node = newHead;
for(int i = 0; i < index.size(); i++) {
if(index[i] == -1) {
node->random = nullptr;
} else {
node->random = nodes[index[i]];
}
node = node->next;
}
return newHead;
}
};
|
性能分析
时间复杂度:在建立索引数组时,每访问一个节点,都需要遍历链表,为O(n2),然后创建新链表,同时将新创建节点指针放入数组中,然后再次遍历设置random指针,时间复杂度为O(n)。所以总的时间复杂度为O(n2)。
空间复杂度:使用了两个数组,一个用来存放索引的数组,一个放节点指针数组,因此空间复杂度为O(n)。
参考做法
共有三种做法:回溯,迭代,迭代的优化(O(1)空间)。
第一种使用到了图的遍历,我没看懂,等我复习了图再更新。
说一下第二种和第三种。
迭代
算法思想
维护一个已访问字典,保持旧节点和新节点的对应。即map集合,key为旧节点,value为新节点。
首先从头开始遍历旧链表:
对于每一个random指针:
- 如果当前节点的random指针指向一个结点j并且j已经被创建过,则直接使用已访问字典该节点的引用
- 如果当前节点的random指针指向的节点 j 还没有被创建,即已访问字典中没有,那么就创建该节点并将其放入字典中,然后同样使用该节点的引用
对于每一个next指针:
- 如果当前节点的next指针指向的节点在已访问字典中存在,则直接使用该节点的引用
- 如果不存在,则创建新节点,同时放入字典中,,并返回该节点引用
当给定链表遍历完毕,复制完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class Solution {
public:
unordered_map<Node *, Node *> visited;
Node * getCloneNode(Node * node) {
if(node != nullptr) {
if(this->visited.count(node)) {
return this->visited[node];
} else {
Node * temp = new Node(node->val);
visited.insert({node, temp});
return temp;
}
}
return nullptr;
}
Node* copyRandomList(Node* head) {
if(head == nullptr) {return nullptr;}
Node * oldHead = head;
Node * newHead = new Node(head->val);
visited.insert({oldHead, newHead});
Node * cur = newHead;
while (oldHead) {
cur->random = getCloneNode(oldHead->random);
cur->next = getCloneNode(oldHead->next);
oldHead = oldHead->next;
cur = cur->next;
}
return newHead;
}
};
|
性能分析
时间复杂度:遍历链表,为O(n)。
空间复杂度:使用map集合,O(n)。
迭代的优化
算法思想
不使用map集合。而是将原链表当做一个map集合。
首先,对于原链表的每个节点,创建一个新节点放在后面。
例如,链表ABCD,则创建后的链表变为:AA BB CC DD。
就是创建一个值相等的节点放在对应结点后面。
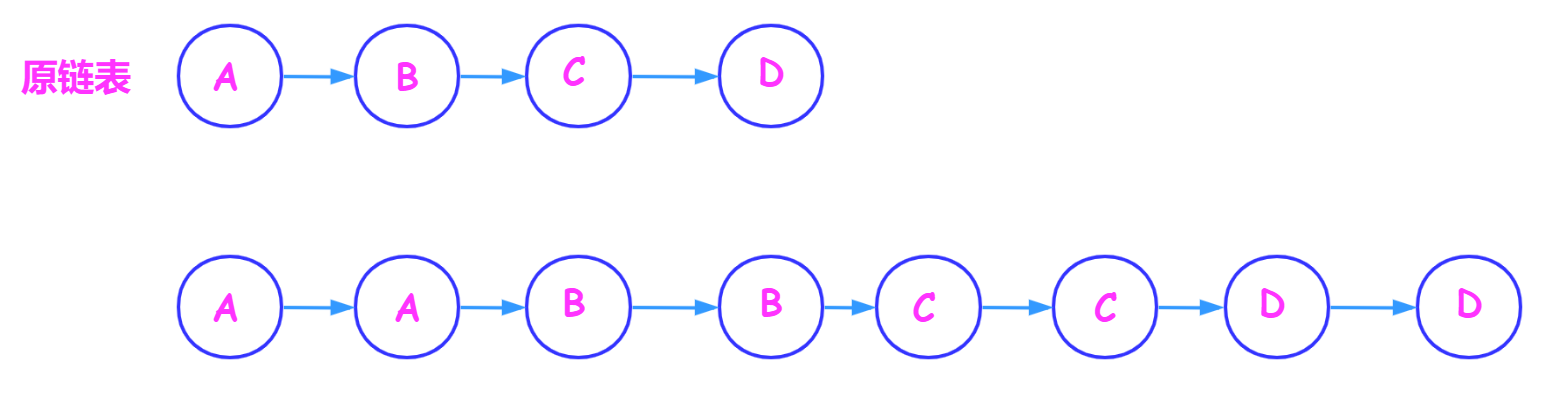
那么令原节点的random指针指向的节点为a,则新创建的节点的random指针应指向``a->next`。
例如图中A节点的random指针指向C,则新创建的节点的random指针指向C节点后面的新创建节点。
next指针也是这个道理。
这样就可以在不借助额外空间的情况下,以原链表作为map集合,直接创建节点并设置对应指针。
巧妙~
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) {
return nullptr;
}
Node * node = head;
while (node) {
Node * temp = new Node(node->val);
temp->next = node->next;
node->next = temp;
node = node->next->next;
}
Node * newHead = head->next;
node = head;
while (node) {
node->next->random = node->random != nullptr ? node->random->next : nullptr;
node = node->next->next;
}
node = head;
while (node) {
Node * rear = node->next->next;
node->next->next = rear != nullptr ? rear->next : nullptr;
node->next = rear;
node = rear;
}
return newHead;
}
};
|
最后旧链表会恢复原状。
性能分析
时间复杂度:O(n)。
空间复杂度:O(1)。